
Interpolation
In many domains of science, measurements are done. If these measurements are drawn in a graph, they will be shown as simple unconnected points. Such data are called data points, or discrete. Handling and analysis of the data is easier, if it can be described using a continuous function, or a line connecting the discrete data point together. In order to do this, the line between two measurements, or data points, need to be created. This process of connecting the data points together with a line called interpolation. There are different ways to invent the data, each method has its benefits and drawbacks. The simplest method is drawing a straight line between two data points, which is not very accurate. Very often, polynomials are used to create a more accurate representation. Even if some of the data is wrong, in many cases, the results of this interpolation are usable, either as a replacement for missing data points, or as a tool to help understand more complicated data.
Interpolation tries to find the values between two known points of data. It is not to be confused with extrapolation, which is a similar process that tries to find data points at the edge or outside the currently defined points.
Uses[change | change source]
The primary use of interpolation is to help users, be they scientists, photographers, engineers or mathematicians, determine what data might exist outside of their collected data. Outside the domain of mathematics, interpolation is frequently used to scale images and to convert the sampling rate of digital signals.
In the domain of science, a scientist may need to use a computer to calculate a complicated function. However, if that function takes a very long time to compute, it may make her experiments difficult or impossible to run properly. So, she might use interpolation to create a slightly less complicated version of her function, which takes less computational time and energy to run. This interpolated function should achieve the same results as the more complex function, but will make some errors, or lose some detail as compared to the original function. However, the reduced time and cost of running the interpolated function may make this trade-off worthwhile.
When an image is made larger, the existing pixels cannot simply be stretched, as you might stretch a rubber band. Instead, new pixels must be created. In order to "guess" what these pixels should look like, the software that enlarges the image uses interpolation. The software first spreads out the existing pixels into the new image size, leaving many gaps and spaces. Then, it examines the existing data (the original pixels) and then creates a function that describes the missing data (the new pixels) to create a new data set (the enlarged image). Sometimes, the program does a poor job, and the resulting image is blurry or wrong in places. These are called interpolation errors - the software did not correctly guess what the data should be. But, overall, the image will look similar. This is an example of the risks and benefits of interpolation - the user can see new data, but that data may not be perfect.
Gallery[change | change source]
-
 Sample measurements, as they may result from an experiment.
Sample measurements, as they may result from an experiment. -
 Piecewise constant interpolation, or nearest-neighbor interpolation.
Piecewise constant interpolation, or nearest-neighbor interpolation. -
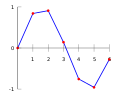 Using straight lines to find the values between two points; this is called linear interpolation
Using straight lines to find the values between two points; this is called linear interpolation -
 Using a polynomial to interpolate.
Using a polynomial to interpolate. -
 Use of a spline to interpolate
Use of a spline to interpolate -
 Interpolation can also be used to resize an image
Interpolation can also be used to resize an image






Further Reading[change | change source]
More about interpolation in graphics and photography: http://www.cambridgeincolour.com/tutorials/image-interpolation.htm